
Page 43 - Kỷ yếu hội thảo khoa học lần thứ 12 - Công nghệ thông tin và Ứng dụng trong các lĩnh vực (CITA 2023)
P. 43
Dinh-Hoang-Long Tran, Quoc-Huy Le 27
which has total 110 samples collected which 50 of them acquire from real life and other
from internet source like Kaggle [11].
from real life therefore all of them were brought from Kaggle.
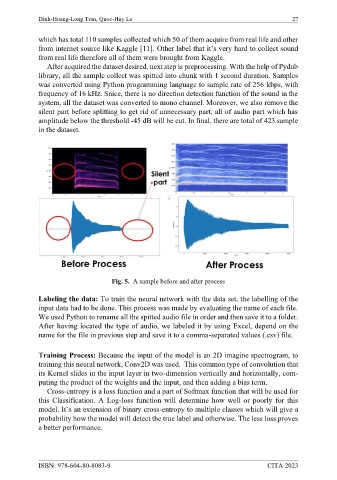
After acquired the dataset desired, next step is preprocessing. With the help of Pydub
library, all the sample collect was spitted into chunk with 1 second duration. Samples
was converted using Python programming language to sample rate of 256 kbps, with
frequency of 16 kHz. Snice, there is no direction detection function of the sound in the
system, all the dataset was converted to mono channel. Moreover, we also remove the
silent part before splitting to get rid of unnecessary part, all of audio part which has
amplitude below the threshold -45 dB will be cut. In final, there are total of 423 sample
in the dataset.
Fig. 5. A sample before and after process
Labeling the data: To train the neural network with the data set, the labelling of the
input data had to be done. This process was made by evaluating the name of each file.
We used Python to rename all the spitted audio file in order and then save it to a folder.
After having located the type of audio, we labeled it by using Excel, depend on the
name for the file in previous step and save it to a comma-separated values (.csv) file.
Training Process: Because the input of the model is an 2D imagine spectrogram, to
training this neural network, Conv2D was used. This common type of convolution that
its Kernel slides in the input layer in two-dimension vertically and horizontally, com-
puting the product of the weights and the input, and then adding a bias term.
Cross-entropy is a loss function and a part of Softmax function that will be used for
this Classification. A Log-loss function will determine how well or poorly for this
-entropy to multiple classes which will give a
probability how the model will detect the true label and otherwise. The less loss proves
a better performance.
ISBN: 978-604-80-8083-9 CITA 2023