
Page 202 - Kỷ yếu hội thảo khoa học lần thứ 12 - Công nghệ thông tin và Ứng dụng trong các lĩnh vực (CITA 2023)
P. 202
186
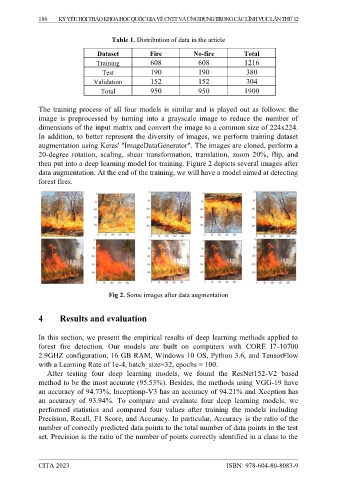
Table 1. Distribution of data in the article
Dataset Fire No-fire Total
Training 608 608 1216
Test 190 190 380
Validation 152 152 304
Total 950 950 1900
The training process of all four models is similar and is played out as follows: the
image is preprocessed by turning into a grayscale image to reduce the number of
dimensions of the input matrix and convert the image to a common size of 224x224.
In addition, to better represent the diversity of images, we perform training dataset
augmentation using Keras' "ImageDataGenerator". The images are cloned, perform a
20-degree rotation, scaling, shear transformation, translation, zoom 20%, flip, and
then put into a deep learning model for training. Figure 2 depicts several images after
data augmentation. At the end of the training, we will have a model aimed at detecting
forest fires.
Fig 2. Some images after data augmentation
4 Results and evaluation
In this section, we present the empirical results of deep learning methods applied to
forest fire detection. Our models are built on computers with CORE I7-10700
2.9GHZ configuration, 16 GB RAM, Windows 10 OS, Python 3.6, and TensorFlow
with a Learning Rate of 1e-4, batch_size=32, epochs = 100.
After testing four deep learning models, we found the ResNet152-V2 based
method to be the most accurate (95.53%). Besides, the methods using VGG-19 have
an accuracy of 94.73%, Inceptionp-V3 has an accuracy of 94.21% and Xception has
an accuracy of 93.94%. To compare and evaluate four deep learning models, we
performed statistics and compared four values after training the models including
Precision, Recall, F1 Score, and Accuracy. In particular, Accuracy is the ratio of the
number of correctly predicted data points to the total number of data points in the test
set. Precision is the ratio of the number of points correctly identified in a class to the
CITA 2023 ISBN: 978-604-80-8083-9